02
Research Areas
Topics of Interest
Visual Arts SegmentationDepth Estimation in Visual ArtsSaliency Detection in Narrative Visual FormsVision-Language Alignment in Arts / Multimodal LearningGenerative Models and 3D Modeling in Visual ArtsProvenance TrackingComputer Vision for Museum Analysis and RestorationAI Ethics in ArtImage Composition
Visual Arts SegmentationDepth Estimation in Visual ArtsSaliency Detection in Narrative Visual FormsVision-Language Alignment in Arts / Multimodal LearningGenerative Models and 3D Modeling in Visual ArtsProvenance TrackingComputer Vision for Museum Analysis and RestorationAI Ethics in ArtImage Composition
001Robust segmentation & depth estimation in stylized imagery
002Saliency detection in narrative visual forms
003Vision–language alignment in art interpretation
004Generative models & 3D modeling from artworks
005Provenance tracking & authenticity verification
006Watermark robustness in AI-generated art
007Computer vision for museum analysis & digitization
008Art restoration & preservation using computer vision
009AI ethics, authorship & responsible AI in creative contexts
010Multimodal reasoning in art & cultural heritage
011Art & animation
012Image composition for visual arts
013Any AI × Visual Art intersection
05Competition
PortraitCraft Challenge
The AI4VA Image Composition Challenge (PortraitCraft) features two competitive tracks that push the boundaries of AI-driven portrait composition understanding and generation. Participants are invited to develop novel methods for analysing and composing portrait imagery in artistic contexts.
BenchmarkDataset Introduction
PortraitCraft is a benchmark dataset for portrait composition understanding and portrait composition generation. It is designed to support models in learning and evaluating composition quality in portrait images. The dataset focuses on images with humans as the primary subjects and covers a wide range of scenarios, including single-person and multi-person portraits, as well as half-body and full-body compositions. It emphasizes key composition factors such as subject prominence, pose quality, image layout, and overall visual atmosphere.
PortraitCraft supports two task directions: portrait composition understanding and portrait composition generation. The dataset is constructed through large-model-assisted filtering combined with evaluation by professional designers, ensuring high-quality samples and fine-grained composition annotations.
Dataset & Baseline
TimelineChallenge Period
Key dates for the PortraitCraft challenge. See the workshop timeline for full paper and workshop dates.
- Start
- April 5, 2026
- End
- May 17, 2026
CompetitionTwo Challenge Tracks
The challenge is organized into two complementary tracks. Participants may choose to focus on structured analysis of existing portraits, generation from composition-oriented specifications, or both.
Challenge Track 1Portrait Composition Understanding
Given a portrait image, predict the overall composition quality score, provide fine-grained attribute judgments, and answer a challenging visual question.
CodaBench: Track 1 competition → Challenge Track 2Portrait Composition Generation
Given structured composition descriptions, generate portrait images that accurately realize the specified layout and aesthetic intent.
CodaBench: Track 2 competition →
Track 1Portrait Composition Understanding
Participate: Track 1 on CodaBench
Introduction
Portrait Composition Understanding aims to evaluate a model's ability to understand portrait composition in a structured and interpretable way. Given a portrait image, participants are required to produce three types of outputs: a predicted overall composition score, ternary judgments on dozens of predefined fine-grained composition attributes, and an answer to a carefully designed visual question that tests detailed understanding of the image content. Unlike traditional aesthetic assessment tasks that focus only on global quality prediction, this track emphasizes both attribute-level composition analysis and fine-grained visual comprehension. The goal is to encourage models that not only estimate how good a portrait is, but also explain why it is good and demonstrate that they truly understand the image.
Model Input and Output
In this track, the model takes a portrait image as input and is required to perform structured composition analysis. The task consists of a training stage and a testing stage.
(1) Training stage. The training data for Track 1 are provided in the form of image-text pairs. Each training sample consists of a portrait image and a corresponding text description. The text includes an overall composition score, the scores of 13 composition attributes, and explanations of these attribute-level judgments.
(2) Test stage. During testing, the model receives a single portrait image as input and is required to produce three types of outputs:
- Overall composition score. The model should predict a single score that reflects the overall quality of the portrait composition.
- Fine-grained attribute judgments. The model should provide ternary judgments for dozens of predefined composition attributes, indicating whether each attribute is good or poor for the given image.
- Visual question answering. The model should answer a carefully designed multiple-choice question related to the image, requiring genuine understanding of the image content.
Together, these three outputs assess global composition evaluation, attribute-level composition reasoning, and detailed visual understanding within a unified framework.
Evaluation Metrics
Submissions will be evaluated using a unified score that jointly considers performance across all three required outputs. The exact weighting and implementation details of the evaluation protocol are not disclosed to ensure fairness and robustness of the benchmark.
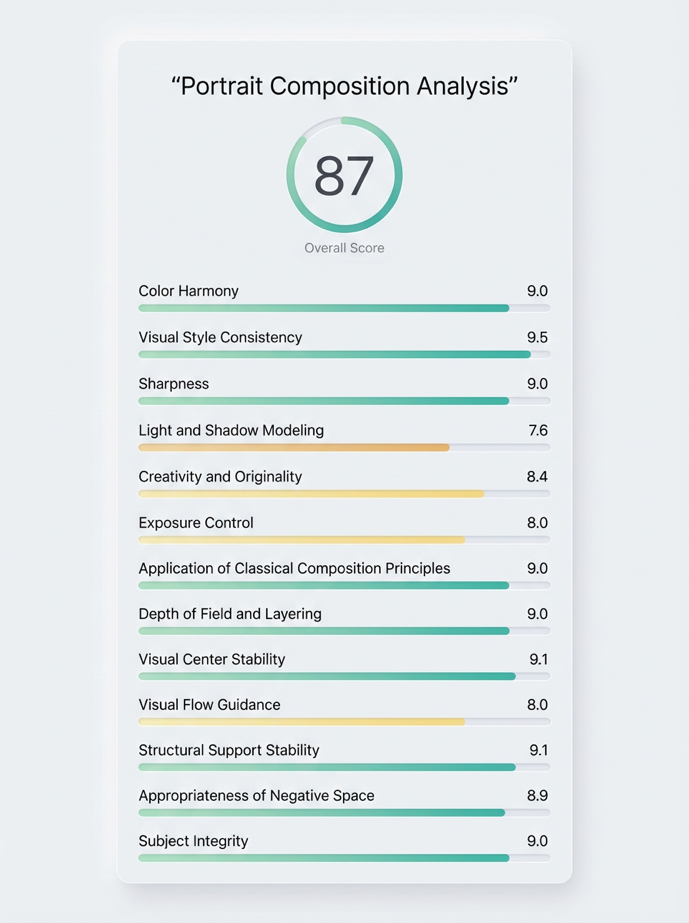
Example
The pair below illustrates an input portrait alongside a visualization of annotation results, highlighting the kinds of fine-grained composition cues the challenge considers.
This figure is for illustration purposes only. Please refer to the official challenge documentation for detailed evaluation specifications.
Track 2Portrait Composition Generation
Participate: Track 2 on CodaBench
Introduction
Portrait Composition Generation evaluates a model's ability to generate portrait images from structured composition-oriented descriptions. Participants are provided with training data consisting of portrait images paired with composition-focused annotations. At test time, only the structured descriptions are given, and models must generate corresponding portraits. This track emphasizes whether models can accurately interpret and realize composition requirements in generated portraits.
Model Input and Output
In this track, the model takes structured composition-oriented descriptions as input and is required to generate corresponding portrait images. The task consists of two stages:
(1) Training stage. Participants are provided with portrait images paired with structured textual descriptions that focus on composition and aesthetic attributes such as subject placement, spatial organization, visual center, negative space, and overall composition style.
(2) Test stage. During testing, only structured composition descriptions are provided. Participants are required to generate portrait images that reflect the specified composition requirements.
Evaluation Metrics
The final score is computed based on the consistency between the generated images and the target structured composition descriptions. The evaluation focuses on whether the generated results accurately reflect the key composition and aesthetic characteristics specified in the descriptions.
Example
Figure 3 shows a reference portrait; Figure 4 shows an image regenerated from a structured composition description.
This figure is for illustration purposes only. Please refer to the official challenge documentation for detailed evaluation specifications.
Structured Description (Excerpt)
Full-body portrait photograph of a young woman dancing gracefully on a long wooden pier extending into shallow turquoise sea water at sunset.
Strong central perspective composition. The pier forms leading lines toward the horizon. The subject is positioned near the center axis of the frame. She stands on one foot with the other leg lifted and bent, arms extended outward in an expressive balanced pose.
A soft, faint rainbow appears diagonally across the sky from the upper-right corner to the lower-left region of the frame, forming a subtle diagonal compositional structure that enhances visual flow without dominating the scene.
…
professional photography, cinematic lighting, diagonal composition, leading lines, central perspective symmetry, elegant movement, balanced composition, subtle rainbow accent, high aesthetic quality, sharp details, realistic style.
Co-organised byMeitu
 Abstraction
Abstraction Heritage
Heritage Narrative
Narrative